mirror of
https://github.com/xhlove/GetDanMu.git
synced 2025-12-18 17:15:57 +08:00
Compare commits
10 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6ab886dd8f | ||
|
|
71c0212fe5 | ||
|
|
e5de08605c | ||
|
|
1c31057b9d | ||
|
|
27de5ce4a3 | ||
|
|
257b9655f0 | ||
|
|
0bd66c894e | ||
|
|
7ce2a35be9 | ||
|
|
986ec2b9fe | ||
|
|
3cfccc1c3c |
38
GetDanMu.py
38
GetDanMu.py
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:39
|
||||
# 上次编辑时间 : 2020-01-11 17:49:40
|
||||
# 上次编辑时间 : 2020-02-07 19:10:02
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
@@ -14,8 +14,12 @@ from argparse import ArgumentParser
|
||||
from sites.qq import main as qq
|
||||
from sites.iqiyi import main as iqiyi
|
||||
from sites.youku import main as youku
|
||||
from sites.sohu import main as sohu
|
||||
from sites.mgtv import main as mgtv
|
||||
from pfunc.cfunc import check_url_site
|
||||
|
||||
from basic.vars import ALLOW_SITES
|
||||
|
||||
# -------------------------------------------
|
||||
# 基本流程
|
||||
# 1. 根据传入参数确定网站,否则请求输入有关参数或链接。并初始化字幕的基本信息。
|
||||
@@ -27,29 +31,49 @@ from pfunc.cfunc import check_url_site
|
||||
|
||||
|
||||
def main():
|
||||
parser = ArgumentParser(description="视频网站弹幕转换/下载工具,任何问题请联系vvtoolbox.dev@gmail.com")
|
||||
parser = ArgumentParser(description="视频网站弹幕转换/下载工具,项目地址https://github.com/xhlove/GetDanMu,任何问题请联系vvtoolbox.dev@gmail.com")
|
||||
parser.add_argument("-f", "--font", default="微软雅黑", help="指定输出字幕字体")
|
||||
parser.add_argument("-fs", "--font-size", default=28, help="指定输出字幕字体大小")
|
||||
parser.add_argument("-s", "--site", default="", help="指定网站")
|
||||
parser.add_argument("-cid", "--cid", default="", help="下载cid对应视频的弹幕(腾讯视频合集)")
|
||||
parser.add_argument("-s", "--site", default="", help=f"使用非url方式下载需指定网站 支持的网站 -> {' '.join(ALLOW_SITES)}")
|
||||
parser.add_argument("-r", "--range", default="0,720", help="指定弹幕的纵向范围 默认0到720 请用逗号隔开")
|
||||
parser.add_argument("-cid", "--cid", default="", help="下载cid对应视频的弹幕(腾讯 芒果视频合集)")
|
||||
parser.add_argument("-vid", "--vid", default="", help="下载vid对应视频的弹幕,支持同时多个vid,需要用逗号隔开")
|
||||
parser.add_argument("-aid", "--aid", default="", help="下载aid对应视频的弹幕(爱奇艺合集)")
|
||||
parser.add_argument("-tvid", "--tvid", default="", help="下载tvid对应视频的弹幕,支持同时多个tvid,需要用逗号隔开")
|
||||
parser.add_argument("-series", "--series", action="store_true", help="尝试通过单集得到合集的全部弹幕")
|
||||
parser.add_argument("-u", "--url", default="", help="下载视频链接所指向视频的弹幕")
|
||||
parser.add_argument("-y", "--y", action="store_false", help="默认覆盖原有弹幕而不提示")
|
||||
parser.add_argument("-y", "--y", action="store_true", help="默认覆盖原有弹幕而不提示")
|
||||
args = parser.parse_args()
|
||||
# print(args.__dict__)
|
||||
init_args = sys.argv
|
||||
imode = "command_line"
|
||||
if init_args.__len__() == 1:
|
||||
# 双击运行或命令执行exe文件时 传入参数只有exe的路径
|
||||
# 命令行下执行会传入exe的相对路径(在exe所在路径执行时) 传入完整路径(非exe所在路径下执行)
|
||||
# 双击运行exe传入完整路径
|
||||
imode = "non_command_line"
|
||||
if imode == "non_command_line":
|
||||
content = input("请输入链接:\n")
|
||||
check_tip = check_url_site(content)
|
||||
if check_tip is None:
|
||||
sys.exit("不支持的网站")
|
||||
args.url = content
|
||||
args.site = check_tip
|
||||
# 要么有url 要么有site和相关参数的组合
|
||||
if args.url != "":
|
||||
args.site = check_url_site(args.url)
|
||||
if args.site == "":
|
||||
args.site = input("请输入站点(qq/iqiyi/youku):\n")
|
||||
elif args.site == "":
|
||||
sys.exit("请传入链接或指定网站+视频相关的参数")
|
||||
if args.site == "qq":
|
||||
subtitles = qq(args)
|
||||
if args.site == "iqiyi":
|
||||
subtitles = iqiyi(args)
|
||||
if args.site == "youku":
|
||||
subtitles = youku(args)
|
||||
if args.site == "sohu":
|
||||
subtitles = sohu(args)
|
||||
if args.site == "mgtv":
|
||||
subtitles = mgtv(args)
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 打包 --> pyinstaller GetDanMu.spec
|
||||
|
||||
90
README.md
90
README.md
@@ -1,19 +1,60 @@
|
||||
<!--
|
||||
* @作者: weimo
|
||||
* @创建日期: 2020-01-04 18:45:58
|
||||
* @上次编辑时间 : 2020-01-11 17:48:19
|
||||
* @一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
-->
|
||||
# GetDanMu
|
||||
|
||||
转换/下载各类视频的弹幕
|
||||
[转换/下载各类视频弹幕的工具][1]
|
||||
|
||||
项目主页:https://github.com/xhlove/GetDanMu
|
||||
|
||||
## 网站支持
|
||||
| Site | URL | 单集? | 合集? | 综艺合集? |
|
||||
| :--: | :-- | :-----: | :-----: | :-----: |
|
||||
| Site | URL | 单集? | 合集? | 综艺合集? | 支持series? |
|
||||
| :--: | :-- | :-----: | :-----: | :-----: | :-----: |
|
||||
| **腾讯视频** | <https://v.qq.com/> |✓|✓| |
|
||||
| **爱奇艺** | <https://www.iqiyi.com/> |✓|✓|✓|
|
||||
| **优酷** | <https://v.youku.com/> |✓|✓|✓|
|
||||
| **爱奇艺** | <https://www.iqiyi.com/> |✓|✓|✓|✓|
|
||||
| **优酷** | <https://v.youku.com/> |✓|✓|✓|✓|
|
||||
| **搜狐视频** | <https://tv.sohu.com/> |✓|✓|||
|
||||
| **芒果TV** | <https://www.mgtv.com/> |✓|✓|✓|✓|
|
||||
|
||||
# 使用示例
|
||||
- 命令(建议)
|
||||
|
||||
> GetDanMu.exe -s mgtv -r 20,960 -series -u https://www.mgtv.com/b/334727/7452407.html
|
||||
|
||||
- 双击运行
|
||||
> 提示逻辑有待完善
|
||||
|
||||
- 选项说明
|
||||
> -f或--font 指定输出字幕字体,默认微软雅黑
|
||||
> -fs或--font-size 指定输出字幕字体大小,默认28
|
||||
> -s或--site 使用非url方式下载需指定网站 支持的网站 -> qq iqiyi youku sohu mgtv
|
||||
> -r或--range 指定弹幕的纵向范围 默认0到720,请用逗号隔开
|
||||
> -cid或--cid 下载cid对应视频的弹幕(腾讯 芒果视频合集)
|
||||
> -vid或--vid 下载vid对应视频的弹幕,支持同时多个vid,需要用逗号隔开
|
||||
> -aid或--aid 下载aid对应视频的弹幕(爱奇艺合集)
|
||||
> -tvid或--tvid 下载tvid对应视频的弹幕,支持同时多个tvid,需要用逗号隔开
|
||||
> -series或--series 尝试通过单集得到合集的全部弹幕 默认不使用
|
||||
> -u或--url 下载视频链接所指向视频的弹幕
|
||||
> -y或--y 覆盖原有弹幕而不提示 默认不使用
|
||||
|
||||
|
||||
- 字体配置文件(可选)
|
||||
新建名为`config.json`的文件,内容形式如下:
|
||||
```json
|
||||
{
|
||||
"fonts_base_folder": "C:/Windows/Fonts",
|
||||
"fonts": {
|
||||
"微软雅黑":"msyh.ttc",
|
||||
"微软雅黑粗体":"msyhbd.ttc",
|
||||
"微软雅黑细体":"msyhl.ttc"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
# 效果示意(字幕与视频不相关)
|
||||
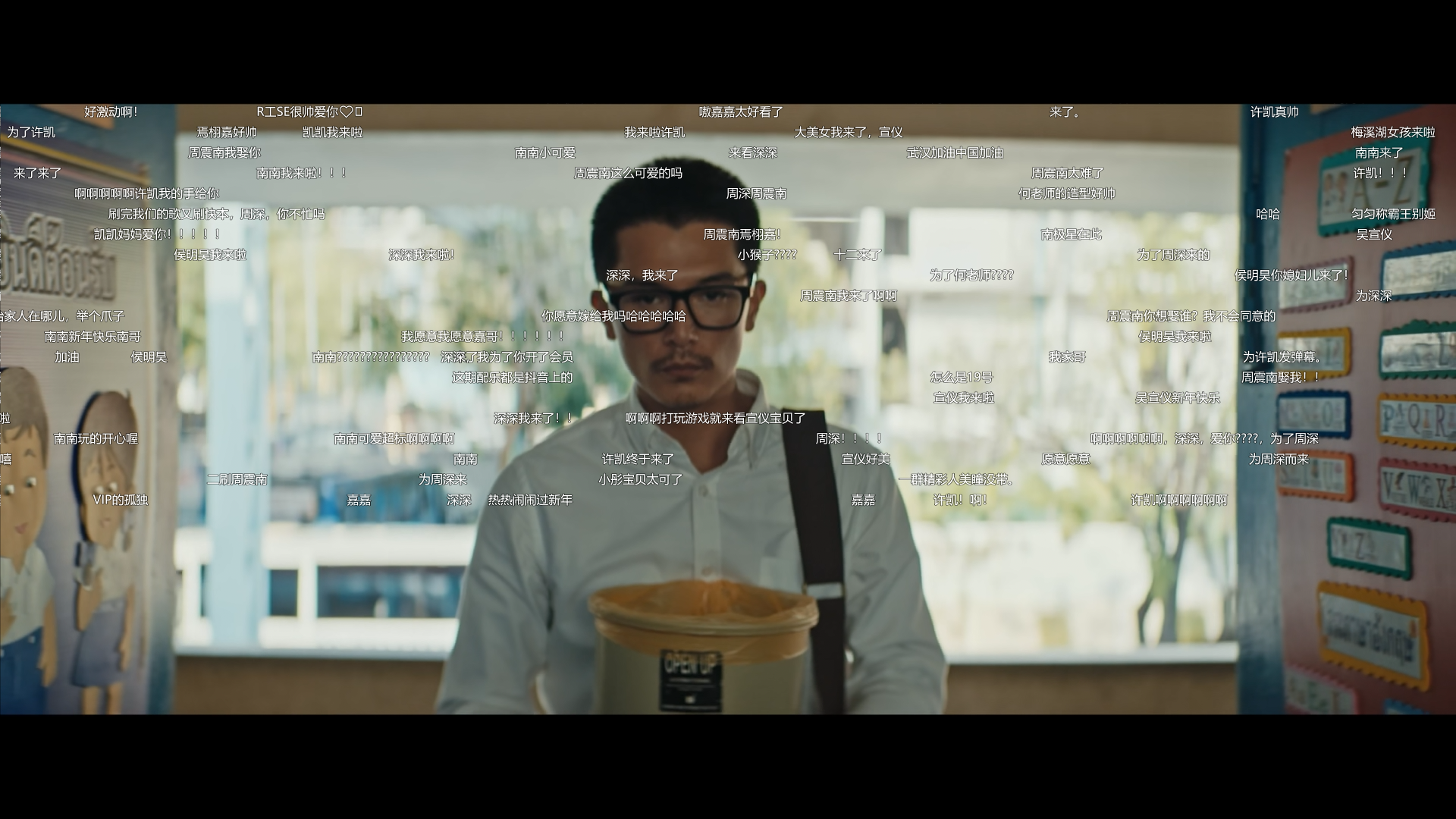
|
||||
[查看使用演示视频点我][2]
|
||||
|
||||
注意有背景音乐
|
||||
|
||||
演示是直接使用的python命令,使用exe的话把python GetDanMu.py换成GetDanMu.exe即可
|
||||
|
||||
## 可能存在的问题
|
||||
- 下载进度接近100%时暂时没有反应
|
||||
@@ -25,6 +66,25 @@
|
||||
|
||||
# 更新日志
|
||||
|
||||
## 2020/2/8
|
||||
- 爱奇艺bug修复
|
||||
|
||||
## 2020/2/7
|
||||
- 完善说明
|
||||
- 爱奇艺支持series选项,并完善地区判断
|
||||
- 增加字体配置文件,建立字体名称与实际字体文件的映射关系,用于预先设定,方便更准确计算弹幕的分布
|
||||
- 增加自定义弹幕区间选项,即-r或--range命令
|
||||
- README完善
|
||||
|
||||
## 2020/1/28
|
||||
- 增加芒果TV的支持(支持综艺合集、支持series命令)
|
||||
- 爱奇艺bug修复
|
||||
|
||||
## 2020/1/16
|
||||
- 增加搜狐视频的支持(剧集)
|
||||
- 改进输入提示(双击运行时)
|
||||
- 腾讯支持-series设定
|
||||
|
||||
## 2020/1/11
|
||||
- 增加优酷弹幕下载,支持合集,支持通过单集直接下载合集弹幕(暂时仅限优酷)
|
||||
- 改进去重方式
|
||||
@@ -34,4 +94,10 @@
|
||||
## 2020/1/5
|
||||
|
||||
- 增加了通过链接下载爱奇艺视频弹幕的方法,支持综艺合集。
|
||||
- 增加通过链接判断网站
|
||||
- 增加通过链接判断网站
|
||||
|
||||
[赞助点此][3]
|
||||
|
||||
[1]: https://blog.weimo.info/archives/431/
|
||||
[2]: https://alime-customer-upload-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/customer-upload/1581073011183_8t14dpgg2bdc.mp4
|
||||
[3]: https://afdian.net/@vvtoolbox_dev
|
||||
28
basic/ass.py
28
basic/ass.py
@@ -3,15 +3,14 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:46
|
||||
# 上次编辑时间 : 2020-01-11 17:20:21
|
||||
# 上次编辑时间 : 2020-02-07 19:21:19
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
import os
|
||||
|
||||
import json
|
||||
from basic.vars import fonts
|
||||
|
||||
|
||||
ass_script = """[Script Info]
|
||||
; Script generated by N
|
||||
ScriptType: v4.00+
|
||||
@@ -30,15 +29,30 @@ ass_events_head = """[Events]\nFormat: Layer, Start, End, Style, Name, MarginL,
|
||||
# 基于当前时间范围,在0~1000ms之间停留在(676.571,506.629)处,在1000~3000ms内从位置1300,600移动到360,600(原点在左上)
|
||||
# ass_baseline = """Dialogue: 0,0:20:08.00,0:20:28.00,Default,,0,0,0,,{\t(1000,3000,\move(1300,600,360,600))\pos(676.571,506.629)}这是字幕内容示意"""
|
||||
|
||||
def get_fonts_info():
|
||||
global fonts
|
||||
fonts_path = r"C:\Windows\Fonts"
|
||||
if os.path.exists("config.json"):
|
||||
with open("config.json", "r", encoding="utf-8") as f:
|
||||
fr = f.read()
|
||||
try:
|
||||
config = json.loads(fr)
|
||||
except Exception as e:
|
||||
print("get_fonts_info error info ->", e)
|
||||
else:
|
||||
fonts_path = config["fonts_base_folder"]
|
||||
fonts = config["fonts"]
|
||||
return fonts_path, fonts
|
||||
|
||||
def get_ass_head(font_style_name, font_size):
|
||||
ass_head = ass_script + "\n\n" + ass_style_head + "\n" + ass_style_base.format(font=font_style_name, font_size=font_size) + "\n\n" + ass_events_head
|
||||
return ass_head
|
||||
|
||||
def check_font(font):
|
||||
win_font_path = r"C:\Windows\Fonts"
|
||||
maybe_font_path = os.path.join(win_font_path, font)
|
||||
fonts_path, fonts = get_fonts_info()
|
||||
maybe_font_path = os.path.join(fonts_path, font)
|
||||
font_style_name = "微软雅黑"
|
||||
font_path = os.path.join(win_font_path, fonts[font_style_name]) # 默认
|
||||
font_path = os.path.join(fonts_path, fonts[font_style_name]) # 默认
|
||||
if os.path.exists(font):
|
||||
# 字体就在当前文件夹 或 完整路径
|
||||
if os.path.isfile(font):
|
||||
@@ -58,7 +72,7 @@ def check_font(font):
|
||||
pass
|
||||
elif fonts.get(font):
|
||||
# 别名映射
|
||||
font_path = os.path.join(win_font_path, fonts.get(font))
|
||||
font_path = os.path.join(fonts_path, fonts.get(font))
|
||||
font_style_name = font
|
||||
else:
|
||||
pass
|
||||
|
||||
@@ -3,9 +3,12 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:35
|
||||
# 上次编辑时间: 2020-01-05 14:46:15
|
||||
# 上次编辑时间 : 2020-02-07 17:57:05
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
ALLOW_SITES = ["qq", "iqiyi", "youku", "sohu", "mgtv"]
|
||||
|
||||
qqlive = {
|
||||
"User-Agent":"qqlive"
|
||||
}
|
||||
|
||||
8
config.json
Normal file
8
config.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"fonts_base_folder": "C:/Windows/Fonts",
|
||||
"fonts": {
|
||||
"微软雅黑":"msyh.ttc",
|
||||
"微软雅黑粗体":"msyhbd.ttc",
|
||||
"微软雅黑细体":"msyhl.ttc"
|
||||
}
|
||||
}
|
||||
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:47
|
||||
# 上次编辑时间: 2020-01-05 14:46:51
|
||||
# 上次编辑时间 : 2020-02-07 18:40:42
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
@@ -14,10 +14,10 @@ class SameHeight(object):
|
||||
'''
|
||||
# 等高弹幕 --> 矩形分割问题?
|
||||
'''
|
||||
def __init__(self, text, font_path="msyh.ttc", font_size=14):
|
||||
def __init__(self, text, ass_range: str, font_path="msyh.ttc", font_size=14):
|
||||
self.font = truetype(font=font_path, size=font_size)
|
||||
self.width, self.height = self.get_danmu_size(text)
|
||||
self.height_range = [0, 720]
|
||||
self.height_range = [int(n.strip()) for n in ass_range.split(",")]
|
||||
self.width_range = [0, 1920]
|
||||
self.lines_start_y = list(range(*(self.height_range + [self.height])))
|
||||
self.lines_width_used = [[y, 0] for y in self.lines_start_y]
|
||||
@@ -49,7 +49,7 @@ class SameHeight(object):
|
||||
def main():
|
||||
text = "测试"
|
||||
show_time = 13
|
||||
sh = SameHeight(text)
|
||||
sh = SameHeight(text, "0,720")
|
||||
sh.get_xy(text, show_time)
|
||||
|
||||
|
||||
|
||||
@@ -3,13 +3,15 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-05 12:45:18
|
||||
# 上次编辑时间 : 2020-01-11 17:37:22
|
||||
# 上次编辑时间 : 2020-01-16 14:50:34
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
import hashlib
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from basic.vars import ALLOW_SITES
|
||||
|
||||
def remove_same_danmu(comments: list):
|
||||
# 在原有基础上pop会引起索引变化 所以还是采用下面这个方式
|
||||
contents = []
|
||||
@@ -23,7 +25,11 @@ def remove_same_danmu(comments: list):
|
||||
return contents
|
||||
|
||||
def check_url_site(url):
|
||||
return urlparse(url).netloc.split(".")[-2]
|
||||
site = urlparse(url).netloc.split(".")[-2]
|
||||
if site in ALLOW_SITES:
|
||||
return site
|
||||
else:
|
||||
return None
|
||||
|
||||
def check_url_locale(url):
|
||||
flag = {
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:17:44
|
||||
# 上次编辑时间 : 2020-01-11 17:25:09
|
||||
# 上次编辑时间 : 2020-02-07 18:17:48
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
import os
|
||||
@@ -17,7 +17,7 @@ def write_one_video_subtitles(file_path, comments, args):
|
||||
# 对于合集则每次都都得检查一次 也可以放在上一级 放在这里 考虑后面可能特殊指定字体的情况
|
||||
font_path, font_style_name = check_font(args.font)
|
||||
ass_head = get_ass_head(font_style_name, args.font_size)
|
||||
get_xy_obj = SameHeight("那就写这一句作为初始化测试吧!", font_path=font_path, font_size=int(args.font_size))
|
||||
get_xy_obj = SameHeight("那就写这一句作为初始化测试吧!", args.range, font_path=font_path, font_size=int(args.font_size))
|
||||
subtitle = ASS(file_path, get_xy_obj, font=font_style_name)
|
||||
comments = remove_same_danmu(comments)
|
||||
for comment in comments:
|
||||
@@ -31,12 +31,16 @@ def write_lines_to_file(ass_head, lines, file_path):
|
||||
for line in lines:
|
||||
f.write(line + "\n")
|
||||
|
||||
def check_file(name, skip=False, fpath=os.getcwd()):
|
||||
def check_file(name, args, fpath=os.getcwd()):
|
||||
flag = True
|
||||
file_path = os.path.join(fpath, name + ".ass")
|
||||
if os.path.isfile(file_path):
|
||||
if skip:
|
||||
if args.y:
|
||||
os.remove(file_path)
|
||||
elif args.series:
|
||||
# 存在重复的 那么直接pass(认为已经下载好了)
|
||||
flag = False
|
||||
return flag, file_path
|
||||
else:
|
||||
isremove = input("{}已存在,是否覆盖?(y/n):".format(file_path))
|
||||
if isremove.strip() == "y":
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:43
|
||||
# 上次编辑时间 : 2020-01-11 17:42:30
|
||||
# 上次编辑时间 : 2020-02-08 21:37:26
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
import re
|
||||
@@ -40,6 +40,28 @@ def get_all_vids_by_column_id():
|
||||
# 综艺类型的
|
||||
pass
|
||||
|
||||
def get_cid_by_vid(vid):
|
||||
api_url = "http://union.video.qq.com/fcgi-bin/data"
|
||||
params = {
|
||||
"tid": "98",
|
||||
"appid": "10001005",
|
||||
"appkey": "0d1a9ddd94de871b",
|
||||
"idlist": vid,
|
||||
"otype":"json"
|
||||
}
|
||||
r = requests.get(api_url, params=params, headers=qqlive).content.decode("utf-8")
|
||||
data = json.loads(r.lstrip("QZOutputJson=").rstrip(";"))
|
||||
try:
|
||||
cid = data["results"][0]["fields"]
|
||||
except Exception as e:
|
||||
print("load fields error info -->", e)
|
||||
return None
|
||||
if cid.get("sync_cover"):
|
||||
return cid["sync_cover"]
|
||||
elif cid.get("cover_list"):
|
||||
return cid["cover_list"][0]
|
||||
return
|
||||
|
||||
def get_all_vids_by_cid(cid):
|
||||
api_url = "http://union.video.qq.com/fcgi-bin/data"
|
||||
params = {
|
||||
@@ -79,7 +101,7 @@ def get_vinfos(aid, locale="zh_cn"):
|
||||
except Exception as e:
|
||||
print("get_vinfos load vlist error info -->", e)
|
||||
return None
|
||||
vinfos = [[v["shortTitle"] + "_" + str(v["timeLength"]), v["timeLength"], ["id"]] for v in vlist]
|
||||
vinfos = [[v["shortTitle"] + "_" + str(v["timeLength"]), v["timeLength"], v["id"]] for v in vlist]
|
||||
return vinfos
|
||||
|
||||
def matchit(patterns, text):
|
||||
@@ -91,7 +113,7 @@ def matchit(patterns, text):
|
||||
break
|
||||
return ret
|
||||
|
||||
def duration_to_sec(duration):
|
||||
def duration_to_sec(duration: str):
|
||||
return sum(x * int(t) for x, t in zip([3600, 60, 1][2 - duration.count(":"):], duration.split(":")))
|
||||
|
||||
def get_year_range(aid, locale="zh_cn"):
|
||||
@@ -112,7 +134,7 @@ def get_year_range(aid, locale="zh_cn"):
|
||||
year_end = int(data["latestVideo"]["period"][:4])
|
||||
return list(range(year_start, year_end + 1))
|
||||
|
||||
def get_vinfo_by_tvid(tvid, locale="zh_cn"):
|
||||
def get_vinfo_by_tvid(tvid, locale="zh_cn", isall=False):
|
||||
api_url = "https://pcw-api.iqiyi.com/video/video/baseinfo/{}".format(tvid)
|
||||
if locale != "zh_cn":
|
||||
api_url += "?locale=" + locale
|
||||
@@ -124,9 +146,32 @@ def get_vinfo_by_tvid(tvid, locale="zh_cn"):
|
||||
data = json.loads(r)["data"]
|
||||
if data.__class__ != dict:
|
||||
return None
|
||||
if isall:
|
||||
aid = data.get("albumId")
|
||||
if aid is None:
|
||||
print("通过单集tvid获取合集aid失败,将只下载单集的弹幕")
|
||||
locale = check_video_area_by_tvid(tvid)
|
||||
if locale is None:
|
||||
locale = "zh_cn"
|
||||
return get_vinfos(aid, locale=locale)
|
||||
name = data["name"]
|
||||
duration = data["durationSec"]
|
||||
return [name + "_" + str(duration), duration, tvid]
|
||||
return [[name + "_" + str(duration), duration, tvid]]
|
||||
|
||||
def check_video_area_by_tvid(tvid):
|
||||
api_url = "https://pcw-api.iqiyi.com/video/video/playervideoinfo?tvid={}".format(tvid)
|
||||
try:
|
||||
r = requests.get(api_url, headers=chrome, timeout=5).content.decode("utf-8")
|
||||
except Exception as e:
|
||||
print("check_video_area_by_tvid error info -->", e)
|
||||
return None
|
||||
data = json.loads(r)["data"]
|
||||
intl_flag = data["operation_base"]["is_international"]
|
||||
langs = [item["language"].lower() for item in data["operation_language_base"]]
|
||||
locale = "zh_cn"
|
||||
if intl_flag is False and "zh_tw" in langs:
|
||||
locale = "zh_tw"
|
||||
return locale
|
||||
|
||||
def get_vinfos_by_year(aid, years: list, cid=6, locale="zh_cn"):
|
||||
api_url = "https://pcw-api.iqiyi.com/album/source/svlistinfo?cid={}&sourceid={}&timelist={}".format(cid, aid, ",".join([str(_) for _ in years.copy()]))
|
||||
@@ -149,7 +194,7 @@ def get_vinfos_by_year(aid, years: list, cid=6, locale="zh_cn"):
|
||||
vinfos.append([ep["shortTitle"] + "_" + str(sec), sec, ep["tvId"]])
|
||||
return vinfos
|
||||
|
||||
def get_vinfos_by_url(url):
|
||||
def get_vinfos_by_url(url, isall=False):
|
||||
locale = check_url_locale(url)
|
||||
patterns = [".+?/w_(\w+?).html", ".+?/v_(\w+?).html", ".+?/a_(\w+?).html", ".+?/lib/m_(\w+?).html"]
|
||||
isw, isep, isas, isms = [re.match(pattern, url) for pattern in patterns]
|
||||
@@ -182,7 +227,7 @@ def get_vinfos_by_url(url):
|
||||
if isep or isw:
|
||||
if tvid is None:
|
||||
return
|
||||
return get_vinfo_by_tvid(tvid, locale=locale)
|
||||
return get_vinfo_by_tvid(tvid, locale=locale, isall=isall)
|
||||
|
||||
if isas or isms:
|
||||
if aid is None:
|
||||
|
||||
3
requirements.txt
Normal file
3
requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
requests==2.22.0
|
||||
Pillow==7.0.0
|
||||
xmltodict==0.12.0
|
||||
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:41
|
||||
# 上次编辑时间 : 2020-01-11 17:23:32
|
||||
# 上次编辑时间 : 2020-02-08 21:37:36
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
@@ -66,8 +66,11 @@ def get_danmu_by_tvid(name, duration, tvid):
|
||||
|
||||
def main(args):
|
||||
vinfos = []
|
||||
isall = False
|
||||
if args.series:
|
||||
isall = True
|
||||
if args.tvid:
|
||||
vi = get_vinfo_by_tvid(args.tvid)
|
||||
vi = get_vinfo_by_tvid(args.tvid, isall=isall)
|
||||
if vi:
|
||||
vinfos.append(vi)
|
||||
if args.aid:
|
||||
@@ -77,13 +80,13 @@ def main(args):
|
||||
if args.tvid == "" and args.aid == "" and args.url == "":
|
||||
args.url = input("请输入iqiyi链接:\n")
|
||||
if args.url:
|
||||
vi = get_vinfos_by_url(args.url)
|
||||
vi = get_vinfos_by_url(args.url, isall=isall)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
subtitles = {}
|
||||
for name, duration, tvid in vinfos:
|
||||
print(name, "开始下载...")
|
||||
flag, file_path = check_file(name, skip=args.y)
|
||||
flag, file_path = check_file(name, args)
|
||||
if flag is False:
|
||||
print("跳过{}".format(name))
|
||||
continue
|
||||
|
||||
206
sites/mgtv.py
Normal file
206
sites/mgtv.py
Normal file
@@ -0,0 +1,206 @@
|
||||
#!/usr/bin/env python3.7
|
||||
# coding=utf-8
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-28 15:55:22
|
||||
# 上次编辑时间 : 2020-02-07 18:32:05
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
import re
|
||||
import json
|
||||
import time
|
||||
import base64
|
||||
import requests
|
||||
from uuid import uuid4
|
||||
from collections import OrderedDict
|
||||
|
||||
from basic.vars import chrome
|
||||
from pfunc.request_info import duration_to_sec
|
||||
from pfunc.dump_to_ass import check_file, write_one_video_subtitles
|
||||
|
||||
pno_params = {
|
||||
"pad":"1121",
|
||||
"ipad":"1030"
|
||||
}
|
||||
type_params = {
|
||||
"h5flash":"h5flash",
|
||||
"padh5":"padh5",
|
||||
"pch5":"pch5"
|
||||
}
|
||||
|
||||
def get_danmu_by_vid(vid: str, cid: str, duration: int):
|
||||
api_url = "https://galaxy.bz.mgtv.com/rdbarrage"
|
||||
params = OrderedDict({
|
||||
"version": "2.0.0",
|
||||
"vid": vid,
|
||||
"abroad": "0",
|
||||
"pid": "",
|
||||
"os": "",
|
||||
"uuid": "",
|
||||
"deviceid": "",
|
||||
"cid": cid,
|
||||
"ticket": "",
|
||||
"time": "0",
|
||||
"mac": "",
|
||||
"platform": "0",
|
||||
"callback": ""
|
||||
})
|
||||
comments = []
|
||||
index = 0
|
||||
max_index = duration // 60 + 1
|
||||
while index < max_index:
|
||||
params["time"] = str(index * 60 * 1000)
|
||||
try:
|
||||
r = requests.get(api_url, params=params, headers=chrome, timeout=3).content.decode("utf-8")
|
||||
except Exception as e:
|
||||
continue
|
||||
items = json.loads(r)["data"]["items"]
|
||||
index += 1
|
||||
if items is None:
|
||||
continue
|
||||
for item in items:
|
||||
comments.append([item["content"], ["ffffff"], int(item["time"] / 1000)])
|
||||
print("已下载{:.2f}%".format(index / max_index * 100))
|
||||
return comments
|
||||
|
||||
def get_tk2(did):
|
||||
pno = pno_params["ipad"]
|
||||
ts = str(int(time.time()))
|
||||
text = f"did={did}|pno={pno}|ver=0.3.0301|clit={ts}"
|
||||
tk2 = base64.b64encode(text.encode("utf-8")).decode("utf-8").replace("+", "_").replace("/", "~").replace("=", "-")
|
||||
return tk2[::-1]
|
||||
|
||||
def get_vinfos_by_cid_or_vid(xid: str, flag="vid"):
|
||||
api_url = "https://pcweb.api.mgtv.com/episode/list"
|
||||
params = {
|
||||
"video_id": xid,
|
||||
"page": "0",
|
||||
"size": "25",
|
||||
"cxid": "",
|
||||
"version": "5.5.35",
|
||||
"callback": "",
|
||||
"_support": "10000000",
|
||||
"_": str(int(time.time() * 1000))
|
||||
}
|
||||
if flag == "cid":
|
||||
_ = params.pop("video_id")
|
||||
params["collection_id"] = xid
|
||||
page = 1
|
||||
vinfos = []
|
||||
while True:
|
||||
params["page"] = page
|
||||
try:
|
||||
r = requests.get(api_url, params=params, headers=chrome, timeout=3).content.decode("utf-8")
|
||||
except Exception as e:
|
||||
continue
|
||||
data = json.loads(r)["data"]
|
||||
for ep in data["list"]:
|
||||
if re.match("\d\d\d\d-\d\d-\d\d", ep["t4"]):
|
||||
# 综艺的加上日期
|
||||
name = "{t4}_{t3}_{t2}".format(**ep).replace(" ", "")
|
||||
else:
|
||||
name = "{t3}_{t2}".format(**ep).replace(" ", "")
|
||||
duration = duration_to_sec(ep["time"])
|
||||
vinfos.append([name, duration, ep["video_id"], ep["clip_id"]])
|
||||
if page < data["count"] // 25 + 1:
|
||||
page += 1
|
||||
else:
|
||||
break
|
||||
return vinfos
|
||||
|
||||
def get_vinfo_by_vid(vid: str):
|
||||
api_url = "https://pcweb.api.mgtv.com/player/video"
|
||||
type_ = type_params["pch5"]
|
||||
did = uuid4().__str__()
|
||||
suuid = uuid4().__str__()
|
||||
params = OrderedDict({
|
||||
"did": did,
|
||||
"suuid": suuid,
|
||||
"cxid": "",
|
||||
"tk2": get_tk2(did),
|
||||
"video_id": vid,
|
||||
"type": type_,
|
||||
"_support": "10000000",
|
||||
"auth_mode": "1",
|
||||
"callback": ""
|
||||
})
|
||||
try:
|
||||
r = requests.get(api_url, params=params, headers=chrome, timeout=3).content.decode("utf-8")
|
||||
except Exception as e:
|
||||
return
|
||||
info = json.loads(r)["data"]["info"]
|
||||
name = "{title}_{series}_{desc}".format(**info).replace(" ", "")
|
||||
duration = int(info["duration"])
|
||||
cid = info["collection_id"]
|
||||
return [name, duration, vid, cid]
|
||||
|
||||
def get_vinfos_by_url(url: str, isall: bool):
|
||||
vinfos = []
|
||||
# url = https://www.mgtv.com/b/323323/4458375.html
|
||||
ids = re.match("[\s\S]+?mgtv.com/b/(\d+)/(\d+)\.html", url)
|
||||
# url = "https://www.mgtv.com/h/333999.html?fpa=se"
|
||||
cid_v1 = re.match("[\s\S]+?mgtv.com/h/(\d+)\.html", url)
|
||||
# url = "https://m.mgtv.com/h/333999/0.html"
|
||||
cid_v2 = re.match("[\s\S]+?mgtv.com/h/(\d+)/\d\.html", url)
|
||||
if ids is None and cid_v1 is None and cid_v2 is None:
|
||||
return
|
||||
if ids and ids.groups().__len__() == 2:
|
||||
cid, vid = ids.groups()
|
||||
if isall:
|
||||
vi = get_vinfos_by_cid_or_vid(vid)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
else:
|
||||
vinfo = get_vinfo_by_vid(vid)
|
||||
if vinfo is None:
|
||||
return
|
||||
vinfos.append(vinfo)
|
||||
if cid_v1 or cid_v2:
|
||||
if cid_v2 is None:
|
||||
cid = cid_v1.group(1)
|
||||
else:
|
||||
cid = cid_v2.group(1)
|
||||
vi = get_vinfos_by_cid_or_vid(cid, flag="cid")
|
||||
if vi:
|
||||
vinfos += vi
|
||||
return vinfos
|
||||
|
||||
def main(args):
|
||||
vinfos = []
|
||||
isall = False
|
||||
if args.series:
|
||||
isall = True
|
||||
if args.url:
|
||||
vi = get_vinfos_by_url(args.url, isall)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
if args.vid:
|
||||
if isall:
|
||||
vi = get_vinfos_by_cid_or_vid(args.vid)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
else:
|
||||
vi = get_vinfo_by_vid(args.vid)
|
||||
if vi:
|
||||
vinfos.append(vi)
|
||||
if args.cid:
|
||||
vi = get_vinfos_by_cid_or_vid(args.cid)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
subtitles = {}
|
||||
for name, duration, vid, cid in vinfos:
|
||||
print(name, "开始下载...")
|
||||
flag, file_path = check_file(name, args)
|
||||
if flag is False:
|
||||
print("跳过{}".format(name))
|
||||
continue
|
||||
comments = get_danmu_by_vid(vid, cid, duration)
|
||||
write_one_video_subtitles(file_path, comments, args)
|
||||
subtitles.update({file_path:comments})
|
||||
print(name, "下载完成!")
|
||||
return subtitles
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = object()
|
||||
args.url = "https://www.mgtv.com/h/333999.html?fpa=se"
|
||||
main(args)
|
||||
31
sites/qq.py
31
sites/qq.py
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-04 19:14:37
|
||||
# 上次编辑时间 : 2020-01-11 17:25:34
|
||||
# 上次编辑时间 : 2020-01-16 20:04:51
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
|
||||
@@ -14,6 +14,7 @@ import requests
|
||||
|
||||
from basic.vars import qqlive
|
||||
from pfunc.dump_to_ass import check_file, write_one_video_subtitles
|
||||
from pfunc.request_info import get_cid_by_vid
|
||||
from pfunc.request_info import get_all_vids_by_cid as get_vids
|
||||
from pfunc.request_info import get_danmu_target_id_by_vid as get_target_id
|
||||
|
||||
@@ -97,10 +98,10 @@ def get_danmu_by_target_id(vid: str, duration: int, target_id, font="微软雅
|
||||
return comments
|
||||
|
||||
|
||||
def get_one_subtitle_by_vinfo(vinfo, font="微软雅黑", font_size=25, skip=False):
|
||||
def get_one_subtitle_by_vinfo(vinfo, font="微软雅黑", font_size=25, args=""):
|
||||
vid, name, duration, target_id = vinfo
|
||||
print(name, "开始下载...")
|
||||
flag, file_path = check_file(name, skip=skip)
|
||||
flag, file_path = check_file(name, args)
|
||||
if flag is False:
|
||||
print("跳过{}".format(name))
|
||||
return
|
||||
@@ -108,7 +109,7 @@ def get_one_subtitle_by_vinfo(vinfo, font="微软雅黑", font_size=25, skip=Fal
|
||||
# print("{}弹幕下载完成!".format(name))
|
||||
return comments, file_path
|
||||
|
||||
def ask_input(url=""):
|
||||
def ask_input(url="", isall=False):
|
||||
if url == "":
|
||||
url = input("请输入vid/coverid/链接,输入q退出:\n").strip()
|
||||
if url == "q" or url == "":
|
||||
@@ -117,6 +118,9 @@ def ask_input(url=""):
|
||||
params = url.replace(".html", "").split("/")
|
||||
if params[-1].__len__() == 11:
|
||||
vids = [params[-1]]
|
||||
if isall:
|
||||
cid = get_cid_by_vid(params[-1])
|
||||
vids += get_vids(cid)
|
||||
elif params[-1].__len__() == 15:
|
||||
cid = params[-1]
|
||||
vids = get_vids(cid)
|
||||
@@ -132,6 +136,9 @@ def ask_input(url=""):
|
||||
|
||||
def main(args):
|
||||
vids = []
|
||||
isall = False
|
||||
if args.series:
|
||||
isall = True
|
||||
if args.cid and args.cid.__len__() == 15:
|
||||
vids += get_vids(args.cid)
|
||||
if args.vid:
|
||||
@@ -141,16 +148,26 @@ def main(args):
|
||||
vids += [vid for vid in args.vid.strip().replace(" ", "").split(",") if vid.__len__() == 11]
|
||||
else:
|
||||
pass
|
||||
if args.series:
|
||||
cid = get_cid_by_vid(args.vid)
|
||||
vids += get_vids(cid)
|
||||
if args.url:
|
||||
vids += ask_input(url=args.url)
|
||||
vids += ask_input(url=args.url, isall=isall)
|
||||
if args.vid == "" and args.cid == "" and args.url == "":
|
||||
vids += ask_input()
|
||||
vids += ask_input(isall=isall)
|
||||
if vids.__len__() <= 0:
|
||||
sys.exit("没有任何有效输入")
|
||||
vids_bak = vids
|
||||
vids = []
|
||||
for vid in vids_bak:
|
||||
if vid in vids:
|
||||
continue
|
||||
else:
|
||||
vids.append(vid)
|
||||
vinfos = get_video_info_by_vid(vids)
|
||||
subtitles = {}
|
||||
for vinfo in vinfos:
|
||||
infos = get_one_subtitle_by_vinfo(vinfo, args.font, args.font_size, args.y)
|
||||
infos = get_one_subtitle_by_vinfo(vinfo, args.font, args.font_size, args=args)
|
||||
if infos is None:
|
||||
continue
|
||||
comments, file_path = infos
|
||||
|
||||
199
sites/sohu.py
Normal file
199
sites/sohu.py
Normal file
@@ -0,0 +1,199 @@
|
||||
#!/usr/bin/env python3.7
|
||||
# coding=utf-8
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-16 17:45:35
|
||||
# 上次编辑时间 : 2020-02-07 18:43:55
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
import json
|
||||
import requests
|
||||
|
||||
from basic.vars import chrome
|
||||
from pfunc.request_info import matchit
|
||||
from pfunc.dump_to_ass import check_file, write_one_video_subtitles
|
||||
|
||||
def try_decode(content):
|
||||
flag = False
|
||||
methods = ["gbk", "utf-8"]
|
||||
for method in methods:
|
||||
try:
|
||||
content_decode = content.decode(method)
|
||||
except Exception as e:
|
||||
print("try {} decode method failed.".format(method))
|
||||
continue
|
||||
flag = True
|
||||
break
|
||||
if flag is True:
|
||||
return content_decode
|
||||
else:
|
||||
return None
|
||||
|
||||
def get_vinfos_by_url(url: str):
|
||||
ep_url = matchit(["[\s\S]+?tv.sohu.com/v/(.+?)\.html", "[\s\S]+?tv.sohu.com/(.+?)/(.+?)\.html"], url)
|
||||
aid_url = matchit(["[\s\S]+?tv.sohu.com/album/.(\d+)\.shtml"], url)
|
||||
vid_url = matchit(["[\s\S]+?tv.sohu.com/v(\d+)\.shtml"], url)
|
||||
if ep_url:
|
||||
try:
|
||||
r = requests.get(url, headers=chrome, timeout=3).content
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print("get sohu (url -> {}) ep url failed.".format(url))
|
||||
return
|
||||
r_decode = try_decode(r)
|
||||
if r_decode is None:
|
||||
print("ep response use decode failed(url -> {}).".format(url))
|
||||
return None
|
||||
vid = matchit(["[\s\S]+?var vid.+?(\d+)"], r_decode)
|
||||
if vid:
|
||||
vinfo = get_vinfo_by_vid(vid)
|
||||
if vinfo is None:
|
||||
return
|
||||
else:
|
||||
return [vinfo]
|
||||
else:
|
||||
print("match sohu vid (url -> {}) failed.".format(url))
|
||||
return None
|
||||
if aid_url:
|
||||
return get_vinfos(aid_url)
|
||||
if vid_url:
|
||||
vinfo = get_vinfo_by_vid(vid_url)
|
||||
if vinfo is None:
|
||||
return
|
||||
else:
|
||||
return [vinfo]
|
||||
if ep_url is None and aid_url is None and vid_url is None:
|
||||
# 可能是合集页面
|
||||
try:
|
||||
r = requests.get(url, headers=chrome, timeout=3).content
|
||||
except Exception as e:
|
||||
print("get sohu (url -> {}) album url failed.".format(url))
|
||||
return
|
||||
r_decode = try_decode(r)
|
||||
if r_decode is None:
|
||||
print("album response decode failed(url -> {}).".format(url))
|
||||
return None
|
||||
aid = matchit(["[\s\S]+?var playlistId.+?(\d+)"], r_decode)
|
||||
if aid:
|
||||
return get_vinfos(aid)
|
||||
return
|
||||
|
||||
|
||||
def get_vinfos(aid: str):
|
||||
api_url = "https://pl.hd.sohu.com/videolist"
|
||||
params = {
|
||||
"callback": "",
|
||||
"playlistid": aid,
|
||||
"o_playlistId": "",
|
||||
"pianhua": "0",
|
||||
"pagenum": "1",
|
||||
"pagesize": "999",
|
||||
"order": "0", # 0 从小到大
|
||||
"cnt": "1",
|
||||
"pageRule": "2",
|
||||
"withPgcVideo": "0",
|
||||
"ssl": "0",
|
||||
"preVideoRule": "3",
|
||||
"_": "" # 1579167883430
|
||||
}
|
||||
try:
|
||||
r = requests.get(api_url, params=params, headers=chrome, timeout=3).content.decode("gbk")
|
||||
except Exception as e:
|
||||
print("get sohu (aid -> {}) videolist failed.".format(aid))
|
||||
return None
|
||||
data = json.loads(r)
|
||||
if data.get("videos"):
|
||||
videos = data["videos"]
|
||||
else:
|
||||
print("videolist has no videos (aid -> {}).".format(aid))
|
||||
return None
|
||||
vinfos = [[video["name"], int(float(video["playLength"])), video["vid"], aid] for video in videos]
|
||||
return vinfos
|
||||
|
||||
|
||||
def get_vinfo_by_vid(vid: str):
|
||||
api_url = "https://hot.vrs.sohu.com/vrs_flash.action"
|
||||
params = {
|
||||
"vid": vid,
|
||||
"ver": "31",
|
||||
"ssl": "1",
|
||||
"pflag": "pch5"
|
||||
}
|
||||
try:
|
||||
r = requests.get(api_url, params=params, headers=chrome, timeout=3).content.decode("utf-8")
|
||||
except Exception as e:
|
||||
print("get sohu (vid -> {}) vinfo failed.".format(vid))
|
||||
return None
|
||||
data = json.loads(r)
|
||||
if data.get("status") == 1:
|
||||
aid = ""
|
||||
if data.get("pid"):
|
||||
aid = str(data["pid"])
|
||||
if data.get("data"):
|
||||
data = data["data"]
|
||||
else:
|
||||
print("vid -> {} vinfo request return no data.".format(vid))
|
||||
return
|
||||
else:
|
||||
print("vid -> {} vinfo request return error.".format(vid))
|
||||
return
|
||||
return [data["tvName"], int(float(data["totalDuration"])), vid, aid]
|
||||
|
||||
def get_danmu_all_by_vid(vid: str, aid: str, duration: int):
|
||||
api_url = "https://api.danmu.tv.sohu.com/dmh5/dmListAll"
|
||||
params = {
|
||||
"act": "dmlist_v2",
|
||||
"dct": "1",
|
||||
"request_from": "h5_js",
|
||||
"vid": vid,
|
||||
"page": "1",
|
||||
"pct": "2",
|
||||
"from": "PlayerType.SOHU_VRS",
|
||||
"o": "4",
|
||||
"aid": aid,
|
||||
"time_begin": "0",
|
||||
"time_end": str(duration)
|
||||
}
|
||||
try:
|
||||
r = requests.get(api_url, params=params, headers=chrome, timeout=3).content.decode("utf-8")
|
||||
except Exception as e:
|
||||
print("get sohu (vid -> {}) danmu failed.".format(vid))
|
||||
return None
|
||||
data = json.loads(r)["info"]["comments"]
|
||||
comments = []
|
||||
for comment in data:
|
||||
comments.append([comment["c"], "ffffff", comment["v"]])
|
||||
comments = sorted(comments, key=lambda _: _[-1])
|
||||
return comments
|
||||
|
||||
def main(args):
|
||||
vinfos = []
|
||||
if args.vid:
|
||||
vi = get_vinfo_by_vid(args.vid)
|
||||
if vi:
|
||||
vinfos.append(vi)
|
||||
if args.aid:
|
||||
vi = get_vinfos(args.aid)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
if args.vid == "" and args.aid == "" and args.url == "":
|
||||
args.url = input("请输入sohu链接:\n")
|
||||
if args.url:
|
||||
vi = get_vinfos_by_url(args.url)
|
||||
if vi:
|
||||
vinfos += vi
|
||||
subtitles = {}
|
||||
for name, duration, vid, aid in vinfos:
|
||||
print(name, "开始下载...")
|
||||
flag, file_path = check_file(name, args)
|
||||
if flag is False:
|
||||
print("跳过{}".format(name))
|
||||
continue
|
||||
comments = get_danmu_all_by_vid(vid, aid, duration)
|
||||
if comments is None:
|
||||
print(name, "弹幕获取失败了,记得重试~(@^_^@)~")
|
||||
continue
|
||||
comments = write_one_video_subtitles(file_path, comments, args)
|
||||
subtitles.update({file_path:comments})
|
||||
print(name, "下载完成!")
|
||||
return subtitles
|
||||
@@ -3,7 +3,7 @@
|
||||
'''
|
||||
# 作者: weimo
|
||||
# 创建日期: 2020-01-05 14:52:21
|
||||
# 上次编辑时间 : 2020-01-11 17:53:14
|
||||
# 上次编辑时间 : 2020-01-16 19:59:08
|
||||
# 一个人的命运啊,当然要靠自我奋斗,但是...
|
||||
'''
|
||||
import re
|
||||
@@ -119,7 +119,7 @@ def main(args):
|
||||
subtitles = {}
|
||||
for name, duration, video_id in vinfos:
|
||||
print(name, "开始下载...")
|
||||
flag, file_path = check_file(name, skip=args.y)
|
||||
flag, file_path = check_file(name, args=args)
|
||||
if flag is False:
|
||||
print("跳过{}".format(name))
|
||||
continue
|
||||
|
||||
Reference in New Issue
Block a user